作者: Jun Han @ 复旦大学
发表在: IEEE 14th International Symposium on Embedded Multicore/Many-core Systems-on-Chip(MPSOC)_2021\
简介
为了满足深度神经网络的实时应用,提出了许多硬件加速器来加速深度神经网络的计算。受加速器微架构的限制,相同的神经网络在不同的加速器上部署时,通常会有巨大的性能差异。为了探索针对硬件的优化,本文基于开源神经网络加速器NVDLA和TVM,设计了一个具有监控功能的全栈异构评估平台。进行了一些实验来证明神经网络如何影响特定硬件设计的性能。实验结果表明,不合适的神经网络结构会在目标硬件上产生额外的数据传输,这是导致性能和能量下降的主要原因。
背景
DNN的硬件加速器主要分为两类,首先是特定算法的加速器(Algorithm-specific accelerator),这种加速器是给应用范围有限的目标算法设计的(例如人脸识别、手势识别),第二种加速器是通用加速器,例如GPU、Google TPU和NVDLA等。由于特定算法专用加速器跟不上深度神经网络发展的步伐,在实际应用中并不实用。而设计一个实用的通用加速器是非常昂贵的。基于上述原因,作者认为设计人员最好花更多的精力调整DNN算法,使其最适合加速器,而不是相反。
为探索神经网络结构算法与硬件架构之间的关系,拓展对目标硬件网络优化空间,本文首先构建了一个基于TVM和NVDLA的全栈评估平台,硬件是异构的,集成了Arm、RISC-V内核和深度学习加速器。然后,本文从硬件结构的角度出发,分析了与硬件结构密切相关的可能的优化方案,并利用评估平台验证了我们的猜想。
全栈异构评估平台
- TVM是一个端到端优化堆栈,它公开了图形级和操作符级优化,为不同硬件后端的深度学习工作负载提供性能可移植性。
- NVDLA是一款由NVIDIA发布的开源的神经网络加速器,是一款由编译器、runtime、firmware和加速器组成的全栈加速器。
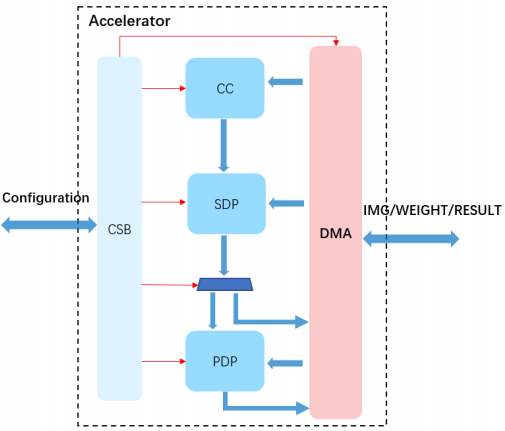
如图所示是NVDLA的计算单元,计算单元主要包含CC(Convolution Core),SDP(Single Point Data Processor)和PDP(Planar Data Processor)
作者的平台如下图所示:
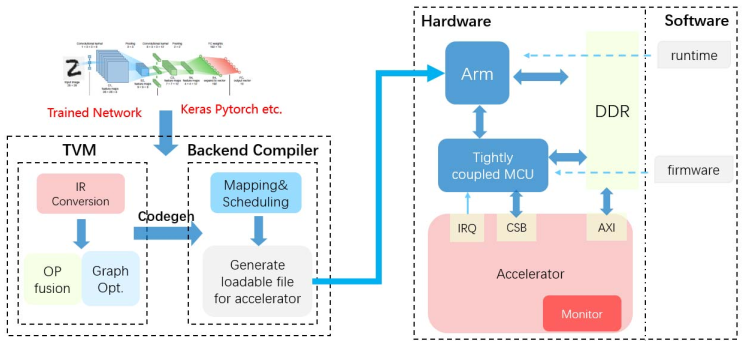
更详细的硬件信息:
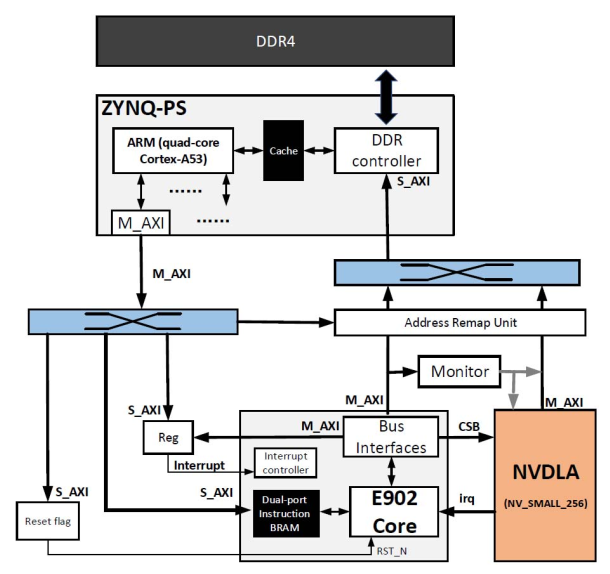
其中包含一个Monitor,用来监控 - CC、SDP、PDP的运行时间和有效计算时间。
- 加速器的有效内存访问次数和总内存访问时间
通过该评估系统,能够获得网络的以下性能指标 - Latency:整个网络计算开始到结果出来的时间
- Computation density:total network operations (FLOPs) / computation time(s)。该指标准确反映了网络在特定硬件上的适应性。对于两个参数数量大致相同的网络,根据其结构,硬件上会发生额外的内存访问操作,导致性能下降。
- DLA的内存访问时间和带宽
- 每个单元的运行时间。该指标反映了网络的计算资源消耗情况,根据该指标可以判断网络的性能瓶颈,从网络角度可以进一步优化网络超参数,提高性能;从硬件的角度来看,应该为长时间运行的部分设计更多的计算资源,下面的实验部分,我们统计了CC的运行时间,SDP和PDP。
作者的实验设计为: - 搭建两个简单的卷积网络,分别采用不同的“Activation→Maxpooling”顺序来执行MNIST分类任务。然后在评估平台上运行这两个模型,使用性能监视器来获取这两个网络的性能指标。
- 构建两个具有相似计算和参数的网络,改变网络的宽度和深度。
- 在平台上运行YOLOv3-tiny和Resnet50对比网络中不可加速算子的运算时间占总运算时间的比值。
作者通过这套评估平台以及上述实验,以MNIST、Yolov3-tiny、Resnet-50等经典网络,验证了DNN的运算顺序、深度和宽度,DNN中包含的算子类型数量,以及不支持的算子数量都会影响性能。